
随着 Nvidia 的每一代 GPU 加速器引擎的推出,机器学习推动了越来越多的架构选择和变化,而传统 HPC 模拟和建模的推动力也越来越少。至少直接上是这样。但间接地,随着 HPC 越来越多地采用 AI 技术,让神经网络从现实世界或模拟数据中学习,而不是运行大量计算来预测某物的行为,HPC 和 AI 之间的差异可能在未来十年左右没有实际意义。
简而言之,英伟达正在豪赌——将其 GPU 计算引擎集中在神经网络转换器模型上,并将其 DGX 系统扩展为能够在机器学习训练运行中支持数万亿个参数。
我们认为,这个是一件好事,因为从长远来看,如果 Nvidia 是正确的,那么在世界各地的 HPC 中心执行的模拟的更多部分将是推断的,而不是数字计算的。虽然密集线性代数计算仍然很重要——尤其是模拟为无法直接查看的物理现象提供数据集,因此没有真实世界的数据——恒星内部或内燃机内部是两个很好的例子—— GPU 上单精度 FP32 和双精度 FP64 数学以及其他类型的数学之间的比率将继续降低到更低的精度。
这肯定发生在新的第四代 Tensor Core 中的新 8 位 FP8 浮点格式上,它是 Nvidia 新的“Hopper”GH100 GPU 芯片的核心。CPU 和 GPU 中向量和矩阵数学单元中的较低精度数据格式,包括 4 位和 8 位整数格式(术语为 INT4 和 INT8),这对 AI 训练没有用处,而仅对 AI 推理有用。但是对于 FP8 格式,对于许多模型来说,大量 FP8 和一些 FP16 以及少量 FP32 和 FP64 的混合现在足以进行训练,而 FP8 也可以用于推理,而不必做繁琐的数据转换为 INT4 或 INT8 格式,以便针对神经网络运行新数据,以便模型识别或转换为另一种类型的数据——语音到文本、文本到速度、视频到语音,
不难想象,有一天Nvidia 可能能够创建一个 GPU 计算引擎,它只具有浮点矩阵数学并支持所有级别的混合精度,可能一直到 FP4,当然也可能一直到 FP64 . 但与其他计算引擎制造商一样,Nvidia 必须保持为其旧设备编写的软件的向后兼容性,这就是为什么我们看到混合使用 32 位和 64 位矢量引擎(它们具有整数支持以及浮点支持)和张量核心矩阵数学引擎。我们之前已经警告过,有很多计算不能在矩阵单元中有效地完成,向量仍然是必要的。(您将不得不原谅我们希望有人创建没有暗硅的最高效数学引擎的热情。)
好消息是,新的“Hopper”GPU 中的流式多处理器或 SM 能够对大量矢量和矩阵数据进行数学运算。
SM 大致类似于 CPU 中的内核,实际上,当您查看 Top500 列表中混合超级计算机的内核数时,该内核数是 CPU 上的内核数和 GPU 上的 SMS 的组合在那个系统中。SM 具有比 CPU 更多的算术单元,并且具有明确设计用于隐藏由相当适中的内核组成的数万个线程的延迟的调度程序,这些内核共同提供比运行的 CPU 一个数量级或更多的性能以大约两倍的速度。对于某些类型的计算来说,更慢更宽比快速和瘦身更好——至少当你受到芯片尺寸、电力消耗和散热的限制,并且你需要扩大到千万亿级和现在的百亿亿级处理时。
这是新的 Hopper SM 的外观:
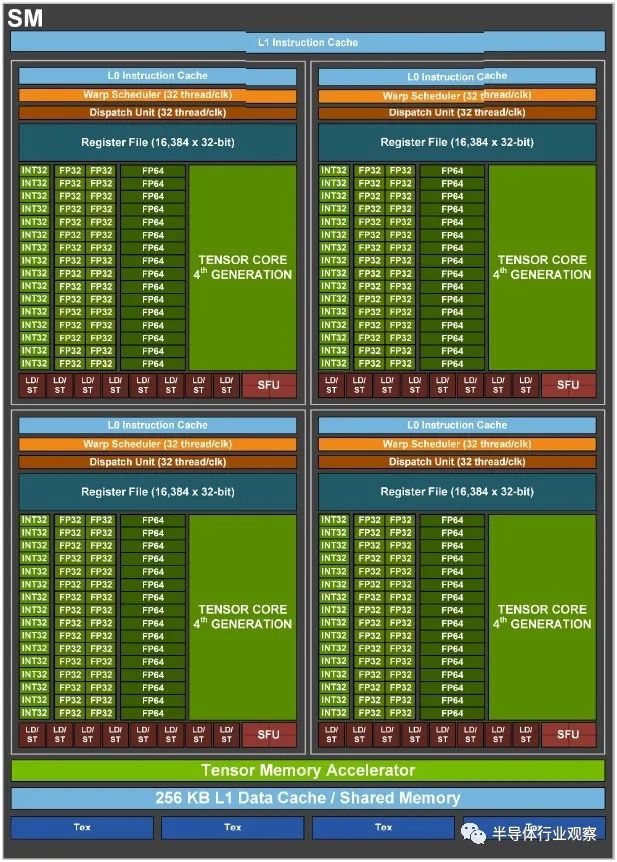

SM 被组织成象限,每个象限有 16 个 INT32 单元,提供混合精度的 INT32、INT8 和 INT4 处理;32 个 FP32 单元(我们希望 Nvidia 不称它们为 CUDA 核心,而是 CUDA 单元);和 16 个 FP64 单元。有一个新的 Tensor Core 设计,Nvidia 故意混淆了这个核心的架构细节。每个象限都有自己的调度器和调度单元,每个时钟可以处理 32 个线程,虽然该调度器可以同时处理多种单元类型,但它不能同时调度所有这些单元。(与“Ampere”GA100 GPU 的比率是调度程序可以同时向五种单元类型中的三种发送工作。我们不知道 GH100 GPU 是什么。)每个 Hopper SM 象限有 16 个,384 个 32 位寄存器,用于维护被推入象限的线程的状态,以及 8 个加载/存储单元和 4 个特殊功能单元。每个象限都有一个 L0 缓存(听起来应该是空的,虽然它不是空的,但我们不知道容量)。SM 由张量内存加速器(稍后会详细介绍)、256 KB 的 L1 数据缓存和未知数量的 L1 指令缓存包裹。(为什么不直接告诉我们?)
大脑很难理解 Tensor Core 是什么,但我们认为它是一个硬编码的矩阵数学引擎,矩阵中的所有输入都来自寄存器,流经单元,它完成了所有同时对矩阵元素进行乘法运算,并一举累积。这与在向量单元中单独排列一些向量、将它们相乘、将结果存储在寄存器中、获取更多向量、进行乘法并通过累积整个 shebang 来完成形成对比。
这是 Nvidia 如何在 4×4 矩阵上使用 FP32 单元来说明 Pascal 矩阵数学,与 Volta Tensor Core 单元和 Ampere Tensor Core 单元相比,这两个单元都硬编码了 4×4 矩阵数学,而后者有一个稀疏数据压缩技巧,可以在不显着牺牲 AI 准确性的情况下使吞吐量翻倍:
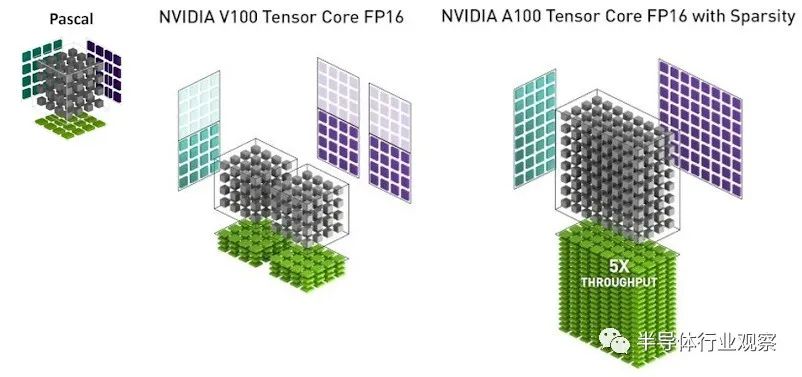
如您所见,Volta Tensor Core 在 FP16 模式下实现了一对硬编码的 4×4 矩阵乘以 4×4 矩阵乘法,FP32 累加。启用稀疏性后,Tensor Core 有效地变成了一个数学单元,相当于对 4×8 矩阵乘以 8×8 矩阵进行计算。
在下面的比较中,Nvidia 似乎展示了 GA100 和 GH100 GPU 的 SM 级别的张量核心,每个都有四个张量核心:
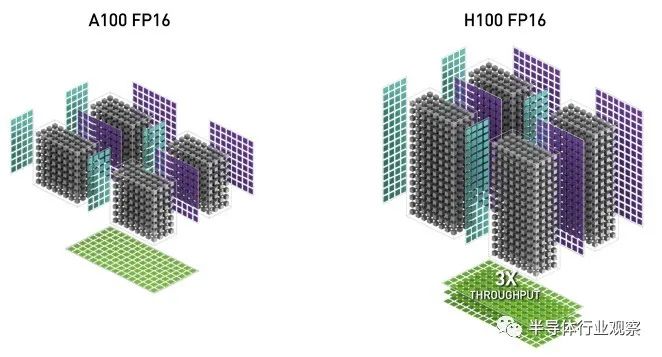
所以我们知道 GA100 每个 SM 有四个张量核心(英伟达在其 GA100 架构论文中透露),我们从这张图推断 GH100 每个 SM 也有四个张量核心(英伟达在其 GH100 架构文件中没有披露) . 我们还可以看到,在稀疏打开的 FP16 模式下,Hopper GPU Tensor Core 有效地将 4×16 矩阵乘以 8×16 矩阵,这是支持稀疏的 Ampere Tensor Core 吞吐量的三倍在。
如果您对所有这些进行数学运算,并为 P100 FP64 矢量引擎分配一个值 1,将 4×4 矩阵乘以另一个 4×4 矩阵,那么 V100 Tensor Core 的功能是 8 倍,A100 Tensor Core 是 20 倍更强大,40X 更强大的稀疏支持(如果适用),H100 Tensor Core 更强大 60X 和 120X 稀疏支持。
物理张量核心的数量因 GPU 架构而异(Volta 为 672,Ampere 为 512,Hopper SXM5 为 576),裸片上激活的核心数量也不同(Volta 为 672,Ampere 为 432,Ampere 为 528 Hopper SXM5。更复杂的是峰值性能比较,GPU 时钟速度也因架构而异:Pascal SXM 为 1.48 GHz,Volta SXM2 为 1.53 GHz,Ampere SXM4 为 1.41 GHz,Hopper SXM5 估计为 1.83 GHz。每个 GPU 的原始张量核心性能上下波动。
就像向量单元越来越宽——128 位、256 位和 512 位——通过它们填充更多的 FP64、FP32、FP16 或 INT8 数字以在每个时钟周期内完成更多工作,Nvidia 正在制造 Tensor Core矩阵更宽更高;大概这可用于对大型矩阵进行数学运算,但也可以将更多较小的矩阵填充到它们中,以使每个时钟完成更多的工作。
重要的是,对于某些类型的矩阵数学,Hopper 只是摒弃了直接使用 FP32 或 FP64 单元来乘数,尽管精度降低了。Tensor Core 还以更高的 FP32 和 FP64 精度运行,支持的 FP32 和 FP64 吞吐量是 GPU 上实际 FP32 和 FP64 单元的两倍。为了保持这个比例正确,Nvidia 不得不不断增加几代的 FP32 内核和 FP64 内核的数量,在 Kepler 到 Hopper 的几代人中平均增加了大约 1.9 倍。
您可以在下面的 Nvidia GPU 计算引擎的计算能力表中看到这一切:
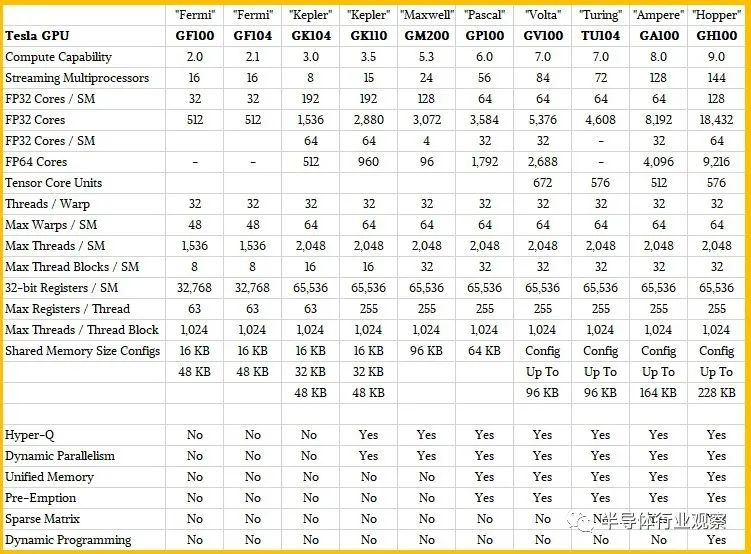
Hopper GH100 GPU 共有 144 个 SM,每个 SM 有 128 个 FP32 内核、64 个 FP64 内核和 64 个 INT32,以及 4 个 Tensor Core。
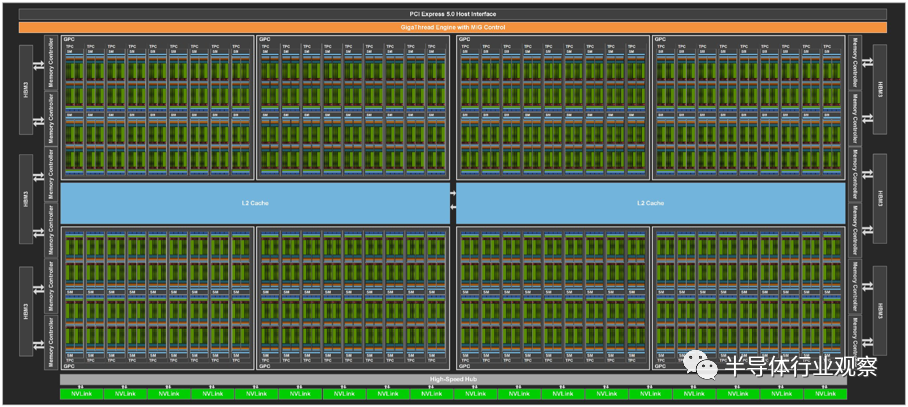
与 GA100 一样,GH100 被组织成 8 个 GPU 处理集群,它们对应于 GH100 可以分割和虚拟化的多实例 GPU (MIG) 分区——现在完全隔离。GPC 有九个纹理处理结构 (TPC),每个由两个 SM 组成。芯片顶部是 uber-scheduler、GigaThread Engine,以及一个 PCI-Express 5.0 主机接口。四个 GPC 排列在一个 L2 缓存组中,有两个组,总容量为 60 MB。
沿着 GA100 GPU 的侧面,有十几个 5,120 位内存控制器,它们馈送到六个 HBM3 内存库。底部是一个高速集线器,所有 GPC 都连接到该集线器,并连接到 18 个 NVLink 4.0 端口,这些端口的总带宽为 900 GB/秒。
为了获得可观的产量,英伟达只销售八分之七的 GPC 和六分之五的 HBM3 内存条和相关的内存控制器工作的 H100。因此,GH100 的 12.5% 的计算能力和 16.7% 的内存容量和带宽是黑暗的——与两年前在 GA100 GPU 上的比例相同。
与其像 Nvidia Research 最近表明的那样,英伟达转向了小芯片,但实际上GH100 是一个单片芯片。
“我们并不反对小芯片,”GPU 工程高级副总裁 Jonah Alben 解释说,他直接指的是联合封装的“Grace”Arm 服务器 CPU 和 Hopper GPU。“但我们真的很擅长制造大芯片,我认为我们在制造大芯片方面实际上比使用 Hopper 时更好。如果你能做到的话,一个大Die仍然是最好的选择,我认为我们比其他任何人都知道如何做到这一点。所以我们以这种方式建造了 Hopper。”
GH100 芯片采用台积电 4 纳米 4N 工艺的定制变体实现,在 SXM4 外形尺寸下消耗 700 瓦,这将内存带宽驱动到 3 TB/秒,而不是 PCI- 中的 2 TB/秒。该卡的 Express 5.0 变体,重量仅为 350 瓦,具有几乎相同的计算性能。
从 Ampere GPU 中使用的 7 纳米工艺缩小到 Hopper GPU 中使用的 4 纳米工艺,Nvidia 能够将更多的计算单元、缓存和 I/O 塞入裸片,同时将时钟速度提高 30% . (英伟达尚未最终确定精确的时钟速度。)
有一大堆新技术使 Hopper GPU 的性能比今年第三季度 Hopper 开始出货时将取代的 Ampere GPU 的性能高出 6 倍。我们已经与Nvidia 的超大规模和 HPC 总经理Ian Buck 讨论了动态编程和 Transformer Engine 加速。但简而言之,Transformer Engine 可以选择性地将新的 8 位 FP8 数据格式应用于机器学习训练或推理工作负载,还可以调用其他降低的精度来加速 Transformer 神经网络模型。重要的是,这种自适应精度是基于在 Selene 超级计算机上进行的大量模拟而动态调整的,以在尽可能提高性能的同时保持精度。
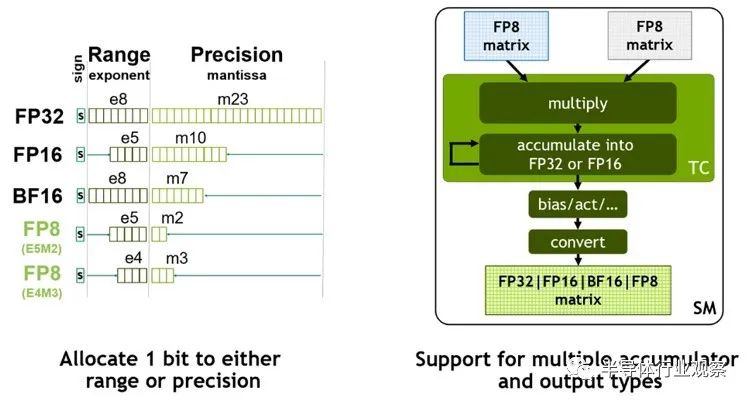
Hopper GPU 中实际上有两种 FP8 格式:一种与 FP16 保持相同的数值范围,但精度大大降低,另一种精度稍高但数值范围较小。Tensor Core 中的 FP8 矩阵数学可以累加成 FP16 或 FP32 格式,并且根据神经网络中的偏差,可以将输出转换为 FP8、BF16、FP16 或 FP32 格式。
当你把它加起来时,转向 4 纳米工艺使 GH100 时钟速度增加了 1.3 倍,SM 的数量增加了 1.2 倍。与 GA100 相比,新的 Tensor Core 以及新的 FP32 和 FP64 矢量单元都提供了 2 倍的每时钟性能提升,对于变压器模型,具有 FP8 精度的 Transformer 引擎将机器学习吞吐量再提高 2 倍。这使得 HPC 常用的矢量引擎的性能提高了 3 倍,而 AI 中常用的 Tensor Core 引擎的性能提高了 6 倍。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至22018681@qq.com 举报,一经查实,本站将立刻删除。
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫