
作者 | 董晓聪
作业帮成立于 2015 年,是一家以科技手段助力普惠教育的公司,公司主要的业务分为两大板块。第一,作业帮 APP 是一款典型的流量互联网产品,二是作业帮直播课,是一款典型的产业互联网产品,涵盖教育主播链条,如教研、教学、教务、辅导等。 我是 2019 年十月份加入作业帮的,当时我看到作业帮的技术现状归纳为两点。一是规模化,另外是复杂化。


规模化:作业帮线上有数千个应用服务,这么多应用服务对应数万个服务实例,这么多的服务实例跑在数十万的计算核心之上;
复杂化:作业帮整体的技术栈是比较多元的。
其中占比最高的技术栈是 Golang 和 PHP,还有大量模块是 C++、Python、Java 等进行编写的,作业帮创业之初就在云上,充分享受了云计算的红利,后来由于一系列原因创建了多元的架构,性能快速迭代也是我们一贯的追求。那为什么要进行降本增效呢?这个事之前也一直在做,只不过今天需要做得更好,其中有几点原因:
第一点,随着互联网红利的消退,企业希望每一分钱得到最大的收益,实现成本效益最大化。第二点,虽然我们一直在强调降本增效,但肯定还是有不必要的支出存在,这些浪费是应该被节省的。第三点,作为技术人员的梦想,还是想写出更优质、更高性能的代码。 在降本增效的过程当中要注意一点,降本不能降质,降低成本时稳定性、效率、安全不能打折扣。我们看一下成本模型。

各种各样的特性和功能应用在计算机上其实是一个一个的代码模块,这些代码其实还是需要各种各样的资源来运作,有计算、存储、网络等等,那么我们看一下这个模型里降本增效怎么来做。
首先公司肯定希望自己的用户越来越多,使用越来越活跃。其次,在应用侧降本增效做的事情就是要提升单位算力承载量,通俗来讲就是 QPS。但我们面临的一个挑战就是作业帮技术栈太多元了,我们如何整体提升?再看资源侧,存储、网络这些资源要么是刚需,要么就是很难控制成本。资源侧降本的重点还是计算资源,而对于计算资源我们需要提升单位成本的算力。
我们面临的挑战是什么呢?就是如何选择更优的机型以及在选择完机型之后,如何让业务更加快速、无感、平滑的过渡过来。在应用和计算资源的中间还有一块巨大的提升空间,就是两者之间的匹配和部署的问题。在部署侧我们也面临一些困难和挑战。

第一,我们在线业务集群的负载并不高。对于高吞吐的业务一般作为核心业务,这些业务要留一定的空闲。对于低负载的业务要有碎片化和长尾化,把线上负载率拉低了。一方面是在线业务负载并不高,另外一方面是大数据离线计算要贴地进行,形成空间不均,还有时间上的不均,互联网业务有明显的波峰波谷。在线教育更加明显,波峰波谷会差两个数量级,我们一直在为波峰进行买单。
如何做到降本增效
上面列举了相关的问题和挑战,作业帮是如何来做的呢?我们选择和阿里云一起,选择开源的力量再结合一定的自研进行相关问题的解决。在应用层面,我们提升了主流技术栈的运行性能,对于使用最多的检索服务进行架构的重构,以此来提升性能和运维效率。

在部署侧,通过 GPU 调度、ECS,在离线混部解决空间和时间的不均。在资源 K8s 技术实现应用透明无感,这样替换机型变得更加快捷。
下面基于应用、部署简单来聊。
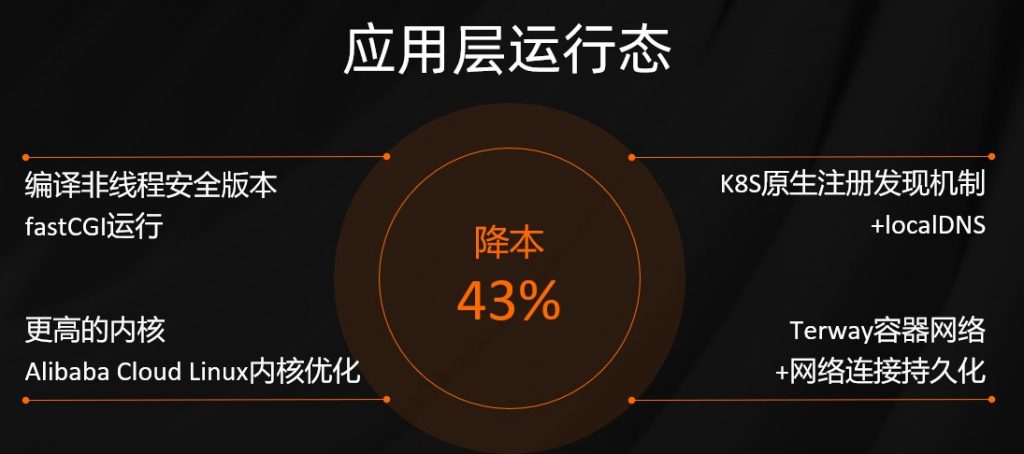
应用这一层对主流技术栈进行优化。第一,我们是重新编译,我们以 FastCGI 运行,对非线程安全进行编译,还有服务注册发现,摒弃之前传统基于名字服务,为了进一步提升性能和成功率,我们还做了 LocalDNS,使用更新的内核 4.10+,和阿里云内核团队进行相应的调优、优化解决一系列问题,解决 IPVS 过多的性能和稳定性问题。
最后得益于 Terway 网络以及网络做的持久化,可以对性能有更明显的提升。完成之后裸框架可以有几倍的提升,可以带来 43% 左右的收益。检索服务作为底层服务,对其性能要求比较高,传统架构一般是计算存储耦合在一起的,随着底下文件数量越来越多,单机无法容纳,要进行切片。每个切片要高可靠、高性能,由此形成二维矩阵,这种情况下存在诸多的问题,比如说像数据更新周期长、整体运维效率并不高,还有系统的瓶颈迟迟得不到解决。
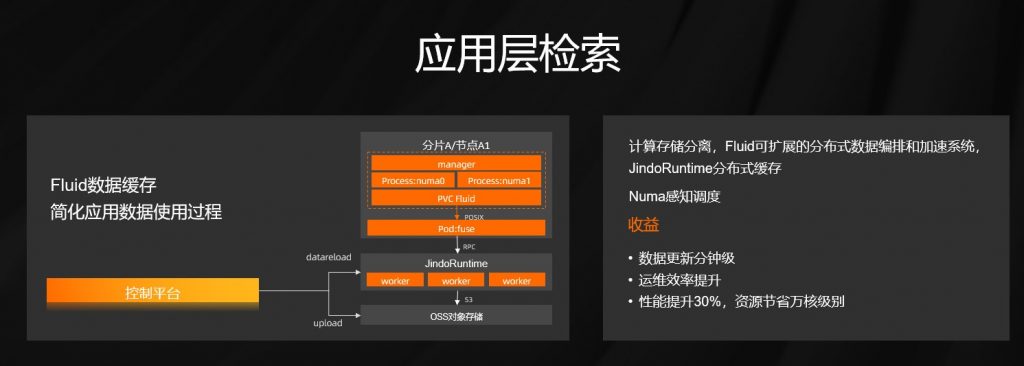
要解决上述问题要做计算和存储的分离,我们引入 Fluid 做一个关键的纽带。Fluid 是一款基于 K8s 的数据编排系统,用于解决云原生过程中遇到的访问数据过程复杂、访问数据慢等一系列问题,JindoRuntime 用于实现缓存的加速,当我们使用 Fliud 和 JindoRuntime 完成整个检索系统的重构之后,获得的收益也比较明显。
首先,作业帮的数据更新周期从之前小时级别缩短到三分钟以内,运维整个机器交付从之前天级别缩短到了小时级别,程序性能也得到大幅度提升,提升比例有 30%,带来了万核级别资源的缩减。
我们再聊一下部署侧,作业帮线上有大量 AI 推理类业务,不光是图像识别 OCR、语音识别、合成这一块。这些业务计算 GPU 长时间脱离整个运维体系,我们希望通过容器化改造将其纳管到统一运维体系里来。我们调研业界主流的技术方案,它们或多或少都会对 GPU 性能造成一定损耗,最后我们选择了阿里云开源方案实现了 GPU Share 的调度方案。

作业帮 GPU 服务所使用的算力和显存相对比较固定,我们就实现了一套匹配机制。类似经典的背包问题。当完成整体一套之后,线上 GPU 资源的使用率得到了大幅度的提升。在离线混部是工程领域比较经典的问题,一方面是在线集群在波谷时有大量的空闲资源,另一方面大数据离线计算需要海量的计算资源,同时离线计算对时级要求并不高,所以两者结合会有双赢的结果。
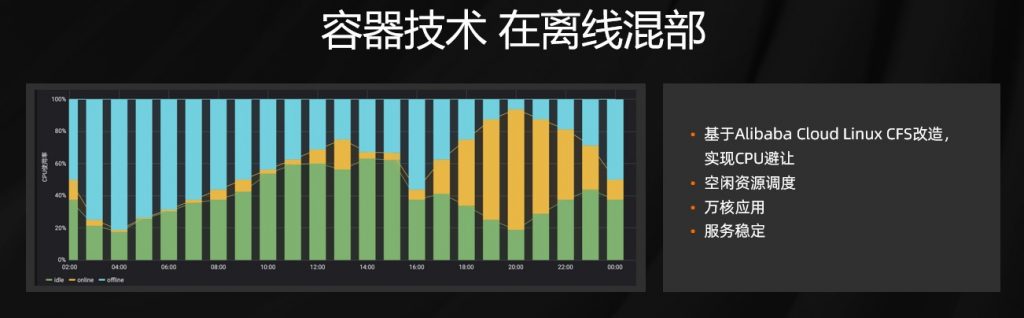
但之前很大的技术瓶颈在于如果混部在一起,离线计算大量消费 CPU 和网络资源,会使得混部的在线资源服务成功率以及时延有大幅度的下降,使用阿里云 CFS 实现 CPU 的避让,实现空白避让以及混部。截止到目前,有万核级别的计算跑在在线集群上,为了进一步保证线上稳定,我们在晚高峰也做实时的调度,将离线计算份额进行缩减,完成这一套之后得到了兼顾稳定性和成本的方案。
作业帮整体 CPU 资源有三个池子,一个是 online CPU 机器,一个是 GPU 的 CPU 机器部分应用起来,第三部分是 ECI ,通过 Pod 数目加减实现策略,包括定时 HP 策略,像一些 AI 模块,只有在固定课程才会应用到,我们提前将课表导入,在上课之前把相关服务提起即可,我们也给线上服务增加一定 AutoHP 的策略。
未来展望
未来,作业帮会将定时业务、AI 计算迁到 ECI 之上来实现真正在线业务的削峰,并且我们将持续探索更具性价比的 IaaS 资源,这也是我们一直尝试和探索的方向。目前,作业帮已经和阿里云有一个关于 AEP 的 tair 方案的结合,在新的一年希望我们有更大规模的落地。文章里讲得比较多的是关于降本做的一些技术改进,其实在降本增效这里面还有很大一块工作量是运营,成本运营我们也通过自动化实现了平台化,未来我们将会进一步向 BI 化、AI 化去演进。
原文链接:301 Moved Permanently
本文为阿里云原创内容,未经允许不得转载。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至22018681@qq.com 举报,一经查实,本站将立刻删除。
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫