
Nvidia不久前发布了下一代GPU架构,架构名字为“Hopper”(为了纪念计算机科学领域的先驱之一Grace Hopper)。根据Nvidia发布的具体GPU规格,我们认为Nvidia对于Hopper的主要定位是进一步加强对于人工智能方面的算力,而其算力升级依靠的不仅仅是硬件部分,还有不少算法和软件协同设计部分,本文将为读者做详细分析。我们认为,在Nvidia更下一代的GPU中,我们有望看到芯粒技术成为新的亮点来突破其瓶颈。
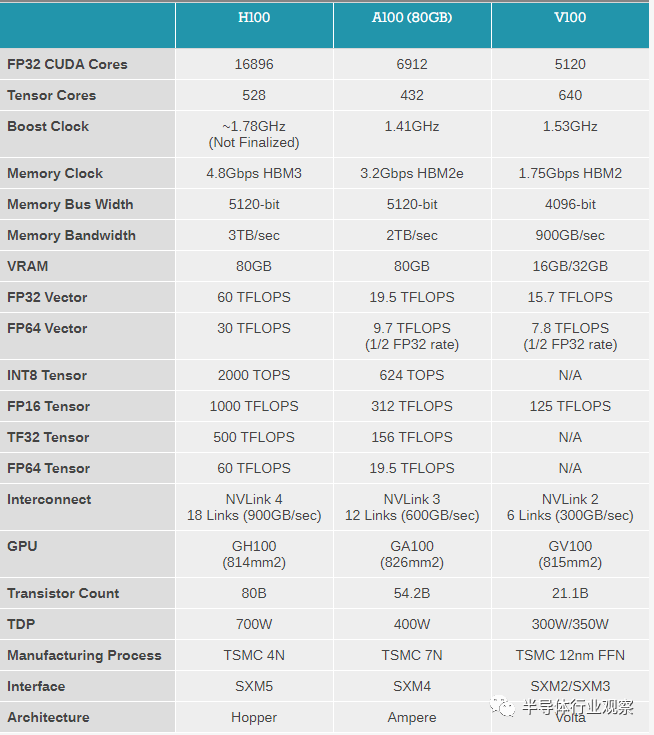

根据Nvidia公布的数据,基于Hopper架构的GPU(H100)使用TSMC的4nm工艺设计,将会是Ampere架构(使用TSMC 7nm工艺)之后的又一次重大升级,其16位浮点数峰值算力(FP16)将会由之前的312 TFLOPS增加到1000 TFLOPS,INT8峰值算力则由之前的624TOPS增加到2000TOPS。由此可见FP16(常用于人工智能训练)和INT8(常用于人工智能推理)的峰值算力基本上都是翻了三倍,这个H100相对A100峰值算力提升的比例基本符合A100和再上一代GPU V100的提升数字。
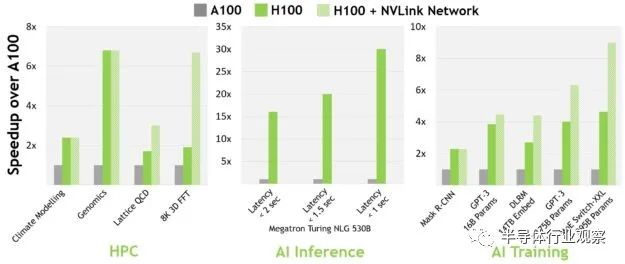
而根据Nvidia官方公布的具体任务性能提升,我们也可以看到大多数人工智能相关任务的性能提升基本在2-4倍之间(尤其是使用transformer类模型的性能提升较为突出,接近4倍),初看也和峰值算力提升三倍基本吻合。但是如果我们仔细分析Nvidia H100具体芯片指标,我们认为在人工智能任务中,H100的提升不仅仅是来自于一些硬件指标(例如核心数量,DRAM带宽,片上存储器)的提升,更是来自于Nvidia做了算法硬件协同设计。例如,Nvidia在Hopper架构中引入了为Transformer系列模型专门设计的八位浮点数(FP8)计算支持,并且还加入了专门的Transformer engine硬件模块来确保transformer模型的运行效率。因此,我们看到在Nvidia公布的人工智能任务性能提升中,使用transformer的任务(如GPT-3)的性能提升要高于传统的基于CNN(如Mask R-CNN)的性能提升。
存储方面提升相对较小
在人工智能等高性能计算中,存储(包括DRAM接口带宽和片上存储容量)和计算单元一样重要,在很多时候存储甚至会成为整体性能的瓶颈,例如峰值算力无法持续,导致平均计算能力远低于峰值算力。在Hopper架构中,我们看到了峰值算力提升大约是Ampere的三倍,然而在DRAM带宽和片上存储方面,Hopper相对于Ampere的提升较小,只有1.5倍和1.25倍。
在DRAM带宽方面,我们看到H100有两个版本,其中使用最新一代HBM3的版本的内存带宽是3TB/s,相比于A100(2TB/s)的提升为1.5倍,相比峰值算力的三倍提升相对较小。反观A100相对更上一代V100的内存带宽提升为2.2倍,因此我们认为H100的HBM3内存带宽提升幅度确实相对上一代来说较小。我们认为,HBM3带宽提升较小可能和功耗有关。
仔细分析Hopper发布的GPU,我们发现Hopper架构的GPU目前有两个品类,一个是使用HBM3内存的版本,而另一个是仍然使用HBM2e的版本。HBM3版本的H100相对于使用HBM2e版本的H100在其他芯片架构上(包括计算单元)的差距不过10%(HBM3版本的计算单元较多),但是在功耗(TDP)上面,HBM3版本的H100的TDP比HBM2e版本H100整整高出两倍(700W vs. 350W)。即使是相对于上一代使用7nm的Ampere架构,其功耗也提高了近两倍,因此能效比方面提升并不多,或者说即使更先进的芯片工艺也没法解决HBM3的功耗问题。因此,我们认为H100 HBM3版本DRAM内存带宽增加可能是受限于整体功耗。而当DRAM带宽提升较小时,如何确保DRAM带宽不成为性能瓶颈就是一个重要的问题,因此Nvidia会提出FP4和Transformer Engine等算法-硬件协同设计的解决方案,来确保在执行下游任务的时候仍然效率不会受限。
除了DRAM带宽之外,另一个值得注意的点是Hopper GPU的片上存储增长仅仅是从A100的40MB增长到了H100的50MB;相对来说,A100的片上存储相对于更上一代V100则是增加了6倍。我们目前尚不清楚H100上片上存储增长这么少的主要原因,究竟是因为Nvidia认为40-50MB对于绝大部分任务已经够用,还是因为工艺良率的原因导致再加SRAM会大大提升成本。
但是,无论如何,随着人工智能模型越来越复杂, 对于片上存储的需求越来越高,片上存储容量较小就会需要有更好的人工智能模型编译器和底层软件库来确保模型执行过程中能有最高的效率(例如,确保能把模型数据更好地划分以尽量在片上存储中执行,而尽可能少地使用DRAM)。Nvidia在这一点上确实已经有了很深厚的积累,各种高性能相关的软件库已经有很好的成熟度。
我们估计Nvidia有强大的软件生态作为后盾也是它有能力在设计中放较少片上存储(以及较小的DRAM带宽)的重要原因。这一点结合之前Nvidia在Hopper引入的新模型-芯片结合设计技术,例如能大大降低内存需求的FP4技术,以及为了Transformer模型专门设计的Transformer Engine,这些其实从正反两面论证了我们的观点,即Hopper架构很多的性能提升事实上是来自于软硬件结合设计,而并非仅仅是芯片/硬件性能提升。
Nvidia下一步突破点在哪里?
如前所述,Nvidia的Hopper架构GPU的芯片领域的突破相比上一代Ampere架构并没有特别大,而是主要由软硬件结合设计实现性能提升。我们看到在存储领域(包括DRAM接口和片上存储容量)的提升尤其小,而这可能也会是Nvidia进一步提升GPU性能的一个重要瓶颈,当然突破了之后也会成为一个重要的技术壁垒。如前所述,HBM3的功耗可能是一个尚未解决的问题,而如何在芯片上放入更多的片上存储器则将会被良率和成本所限制。
在存储成为瓶颈的时候,芯片粒(chiplet)将会成为突破瓶颈的重要技术。正如之前所讨论的,当片上存储容量更大时,GPU对于DRAM等片外存储的需求就会越来越少,而片上存储的瓶颈则是良率和成本。一般来说,芯片的良率和其芯片面积成负相关,当芯片面积越大时,则芯片良率会相应下降,尤其是在先进工艺中,良率更是一个重要考量。而芯片粒则是可以大大改善这个问题:芯片粒技术并不是简单地增加芯片的面积(例如更多片上存储),而是把这些模块分散在不同的芯片粒中,这样一来整个芯片粒的芯片面积就会大大下降,从而改善良率。
此外,随着GPU规模越来越大,为了能更好地控制整体良率,使用芯片粒技术也是一个自然地选择。我们认为,在今天HBM3技术的功耗遇到瓶颈的时候,或者说HBM技术整体从功耗上遇到挑战的时候,下一步的重要方向一定是从简单地增加DRAM带宽和在单个芯片上放更多晶体管变到更精细地设计架构和片上存储,这也就让芯片粒占到了舞台中央。
事实上芯片粒和GPU的结合对于业界来说并不陌生。事实上Nvidia最有力地竞争对手AMD已经把芯片粒技术使用在GPU上,此外在片上存储部分AMD也发布了3D V-Cache,可望成为下一代继续增加片上存储的重要技术。Nvidia在芯片粒方面也有相关布局,这次与Hopper同时间发布的用于芯片粒互联的UCIe标准也意味着Nvidia在芯片粒领域的投资。我们认为,在Nvidia未来公布的GPU中,非常有可能可以看到芯片粒技术的大量应用,而这结合Nvidia的软硬件协同优化技术有可能会成为下一代Nvidia GPU的最大亮点。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至22018681@qq.com 举报,一经查实,本站将立刻删除。
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫